
Alexandru Jerpelea, elevul de 17 ani care a creat primul traducator de aromana: ,,Suntem fericiti ca...
Alexandru Iulius Jerpelea are 17 ani si a creat un traducator pentru limba aromana. Am stat de vorba cu el ca sa intelegem ce l-a motivat si cum a decurs procesul de creatie.&
Alex a invatat despre aromana la scoala. Dupa ce a auzit o prietena de-ale mamei sale vorbind in aromana la telefon, a inceput sa caute si mai multe despre aceasta limba, descoperind si altele in pericol de disparitie, din cauza lipsei masurilor de conservare.
Elev in clasa a XII-a la Colegiul National de Informatica Tudor Vianu din Bucuresti si pasionat si de NLP (n.r. - ,,natural language processing"), adica procesarea limbajului natural prin metode computationale, s-a intrebat ce ar putea face pentru a sprijini procesul de conservare a limbii aromane.&
Conform istoricilor, aromanii erau imprastiati prin Balcani inca din Evul Mediu. In Romania, sunt denumiti popular si romani macedoneni, macedo-romani sau macedono-vlahi. Numarul membrilor comunitatii este dificil de stabilit, din cauza casatoriilor mixte si a folosirii rare a acestei limbi.
Alex a inceput sa lucreze la traducator in ianuarie 2024 si l-a terminat in septembrie, asa ca am stat de vorba cu el, ca sa intelegem cum a decurs procesul si cum a reusit un elev de 17 ani sa construiasca un astfel de produs.&
Libertatea: Povesteste-mi putin despre cum te-ai hotarat sa creezi traducatorul si ce te-a motivat sa pornesti proiectul.
Alex Jerpelea: A inceput prin faptul ca eu deja stiam de aromana de la scoala, dar nu stiam ca e in pericol de disparitie, ca sunt foarte putine resurse digitale. In acelasi timp eram si pasionat de domeniul care se numeste ,,Natural Language Processing", pe scurt NLP. Practic, orice fel de procesare a limbajului natural, uman, prin metode computationale.&
Si apoi, am auzit, intr-adevar, conversatia unei prietene de-ale mamei la telefon, fix atunci cand studiam eu despre acest NLP si vazusem ca exista niste initiative asemanatoare si in America pentru limba cherokee, care, iarasi, este intr-o situatie mult mai dificila, dar acolo se si iau alte masuri de conservare.
N-avea cum sa-mi vina o asemenea idee daca nu mai studiasem chestii similare si nu eram la curent cu subiectul. Nu mi-a venit instant, mi-a venit afland ulterior acasa despre situatia aromanilor, lucru care m-a indemnat sa studiez. Cred ca multi romani au cunoscuti aromani.&
- Parintii tai cum au reactionat la initiativa asta? Mai ales ca ai si dus-o la bun sfarsit cu un asa rezultat.
& - Sunt mandri si ma bucur ca m-au sustinut, nu mi-au zis sa ma las, ca ar fi o prostie sau ceva.
- Care a fost primul pas in dezvoltarea traducatorului?
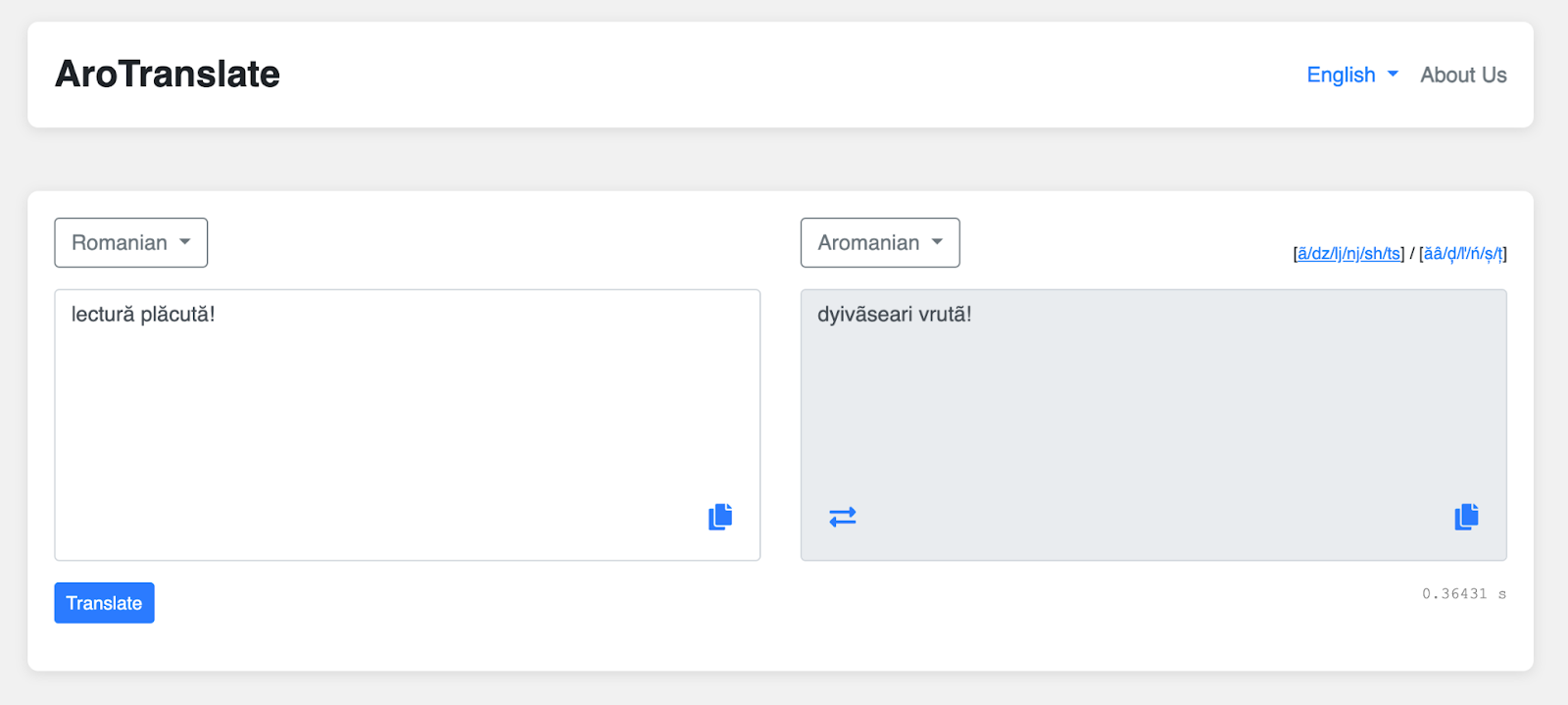
- Primul pas pentru a face un proiect de ,,machine translation" (n.r. - traducere automata) este sa ai un set de date cu propozitii care sa fie paralel traduse in ambele limbi intre care vrei sa faci un sistem de tradus. Iar acestea nu existau.&
E mai important decat inteligenta artificiala, decat orice tehnologii am folosit, care sunt oarecum standard, caci nu e spatiu foarte mare de creativitate.
De-abia prin luna mai, cand eu eram la mijlocul proiectului, a aparut o publicatie care a adunat vreo 3.000 de astfel de propozitii, ceea ce este foarte putin. Deci primul pas a fost colectarea datelor.
Poti sa fii foarte flexibil cand cauti date. Eu, evident, sprijinit, am colectat tot felul de texte. De exemplu, sunt carti de poezii consacrate comunitatii de aromani, care sunt traduse bilingv, adica pe partea stanga a paginii ai in aromana si pe partea dreapta in romana. O tehnica pe care o poti aplica este sa extragi texturi din imagine, sa-ti dai seama carui vers in aromana ii corespunde versul in romana, sa le imperechezi. Asta e un exemplu mai simplu.&
Mai avem carti de proza sau articole jurnalistice, exista presa in aromana. Dar cum iti dai seama daca doua titluri sunt similare, unul aroman si roman pentru a imperechea articolele intre ele, atunci cand nu exista o corespondenta unu la unu intre ele? Pai, cu alte date pe care le-am strans, am antrenat alte modele care sa-si dea seama de similaritatea semantica a doua propozitii.
Cu aceeasi tehnologie, apoi, cand ai doua articole, nu poti sa le spargi in propozitii si sa zici ca prima e cu prima, a doua cu a doua. Ca de multe ori traducerile se fac mai liber si traducatorul poate sa aleaga sa mai sparga o propozitie, sa mai uneasca, sa omita ceva.&
Si aici iarasi am aplicat tehnicii de NLP, folosind tot niste modele care transforma propozitii in vectori numerici, care reprezinta semnificatia semantica, intr-un mod oarecum ascuns. Si apoi, se compara propozitie cu propozitie. Pe scurt, am dezvoltat si unelte de aliniere a doua articole, sa zic asa, in cele doua limbi.& &
De asemenea, eu nu pot sa antrenez traducatorul doar cu texte din Biblie, fiindca toate traducerile apoi vor arata ca o prelegere bisericeasca. Trebuie cumva sa diversifici, sa stii cum sa faci incat sa prinzi erori.&
- Ce a urmat dupa?
- Pasul asta a durat destul de mult. Textele sunt rare, sunt carti pe care le gasesti greu, scanate prost, asa ca aici ne-a ajutat Comunitatea Aromanilor din Romania.
Si ziceam mai devreme ca a facut cineva un asemenea corpus deja prin mai, si anume domnul Sergiu Nisioi, profesor asociat la Universitatea Bucuresti, din cadrul Centrului de Cercetare a Tehnologiilor de Limbaj Uman.&
L-am contactat sa colaboram. Am vazut ca si el a inceput ceva asemanator si mi s-a parut interesant. Dar asta deja cand eram mai avansat, caci el a facut asta in luna mai, dar eu l-am descoperit prin iulie, cand aveam deja un traducator si niste texte.&
Dupa colectarea datelor, urmeaza experimentele cu tot felul de modele din industrie care deja au cunostinte lingvistice, ca sa zic asa, ca sa putem exploata cum intelege un model de inteligenta artificiala limbajul uman si sa beneficieze astfel de ,,transfer learning" (n.r. - invatare prin transfer).&
Am antrenat in continuare modelele existente, pentru a incorpora si aromana. Am si extins la limba engleza, desi noi aveam doar perechi, aromana-romana, le-am tradus artificial si din romana in engleza. Si acum aveam, practic, perechi de cate trei si puteam sa inaintam in toate cele sase directii dintre cele trei limbi.&
Google si ChatGPT si-ar putea imbunatati traducerea in aromana
- Inteleg ca primul pas a fost, de fapt, si cel mai dificil, sa aduni texte si propozitii.
- Cred ca da, sa fiu sincer. Pentru a doua parte, exista multi experti care o puteau face, inclusiv Google, insa n-a facut asta pana acum pentru ca nu existau date pe asa ceva. Acum, ca o sa ne publicam corpusul, este foarte posibil chiar ca Google sau o alta platforma sa gaseasca si sa ,,prinda" informatiile cu ajutorul ,,crawl"-erelor. Mai e posibil ca alte companii care dezvolta ,,language models", cum ar fi OpenAi cu ChatGPT, sa ne preia corpusul.&
Si atunci o sa vedem, poate la ChatGPT, capabilitati mai sporite de a traduce aromana. Noi am testat inclusiv asta in studiul nostru si am ajuns la concluzia ca exista ceva acolo. ChatGPT clar foloseste notiuni de baza de a traduce aromana, doar ca mult mai slabe decat ce am facut noi, din cate am experimentat cu metrici si chestii standard.
- Ce alte cunostinte trebuie sa ai ca sa poti dezvolta un astfel de produs si ce ai invatat pe parcurs?
- Am capatat foarte multe cunostinte. Daca m-as apuca astazi de acest proiect, ar fi ceva mai rapid. M-a ajutat backgroundul de olimpiade de informatica, dar si toata gandirea asta algoritmica te ajuta in a aborda astfel de probleme.&
Apoi trebuie sa inveti foarte multe lucruri de inteligenta artificiala. Trebuie sa intelegi cum functioneaza aceste modele de limbaj care au luat acum lumea prin surprindere, sa zic asa. Sa intelegi foarte multe chestii de statistica si de date.&
Apoi, ca sa antrenam modelele astea, asa ceva nu prea se face pe calculatorul personal, fiindca sunt niste chestii destul de grele, trebuie sa stii cum sa operezi cu un server remote pentru antrenare pe placi video puternice, care de obicei vin contra cost, dar aici am fost iar ajutati de domnul Sergiu Nisioi si institutul din spate.&
Apoi, am invatat foarte mult despre aromana, evident. Printre provocarile principale intervine faptul ca aromana nu este absolut deloc standardizata si ca fiecare vorbitor este cumva influentat de propria limba.&
Adica un roman din Grecia va vorbi mai grecizat, pe cand un roman din Romania va vorbi mai romanizat. Ei au si niste subdialecte ale lor. Si aici apar diferente. Noi am incercat sa studiem cum apar dialectele astea, inclusiv in traducerile noastre. Nu prea am ajuns la o concluzie, din pacate.&
Apoi mai este grafia (n.r. - caracterul executarii literelor in scris) in care se scria aromana, caci nu este standardizata din punctul asta de vedere. Grecii o scriu cu litere grecesti, cei din Romania o scriu cum se scrie si romana.&
Multi altii o scriu cu o ortografie numita cunia, care foloseste doar alfabetul englez. A trebuit sa ne dam seama cum facem conversia intre grafiile astea, fiindca de multe ori este ambigua. Adica stiu ca pe litera ,,s" o fac ,,sh", dar ,,a" il fac ,,a" sau ,,a"? Acolo se pierde o informatie lingvistica.
Nu exista masuri care sa combata scaderea numarului de vorbitori de aromana&
- Dupa ce ai dat drumul traducatorului, ai primit feedback din partea comunitatii de aromani de la noi? A celor din strainatate?
- Da, clar! Am fost bombardati de comunitate cu mesaje si suntem fericiti ca am produs un asa entuziasm. Aromanii sunt foarte pasionati de limba si cultura lor si noi ne bucuram ca, prin asta, am putut sa mai aducem niste atentie in jurul aromanei. Este studiat faptul ca numarul de vorbitori scade dramatic, dar putine masuri sunt luate. Cel mai mult lucreaza ONG-urile, dar si ele fac cat pot.
Am primit mii de felicitari, iar multi credeau ca sunt aroman. Am fost contactati de foarte multi oameni care vor sa ne ajute si suntem foarte recunoscatori pentru asta.
Programul, antrenat sa traduca propozitii, nu cuvinte
- Din ce am inteles, traducatorul are totusi niste limite.
- Da. Noi participam si la o conferinta academica, la ,,COLING 2025" de la Abu Dhabi, pentru care am pregatit si un corpus, validat nu doar automat, ci si de trei evaluatori umani, pe care i-am pus sa adnoteze cu o metodologie destul de standard in industria asta de ,,machine translation".
Concluziile au fost ca functioneaza mai bine cand se traduce spre o limba mai bogata in resurse, adica e mai completa traducerea din aromana in romana sau in engleza, decat invers.
O alta concluzie este ca nu prea se pot traduce cuvinte. Adica nu recomandam ca oamenii sa foloseasca traducatorul nostru ca un dictionar, pentru ca el a fost antrenat sa traduca propozitii.&
La propozitiile mai complexe, mai lungi, sau care contin neologisme, tendinta este ori de romanizare a textului, ori apar aberatii. Aberatiile nu sunt excluse, sunt o problema specifica, ele se mai numesc si ,,hallucinations". Traducatorul e o unealta si poate sa aiba o influenta la cum se dezvolta limba, iar noi nu vrem ca aromana sa se romanizeze din cauza noastra. Am mentionat asta si pe site.
Nota: Am folosit termenul de ,,limba" aromana si nu ,,dialect" deoarece in materialul de fata nu disputam statutul de limba sau dialect (aromanii sustinand statutul de limba), ci punem accent pe faptul ca exista o noua unealta care ajuta la conservarea aromanei.






Comments